To begin, one should chose the nematode clade then the organism C. elegans, a version of genome sequence assembly (e.g. WS220), and a region of the genome. Browser behavior is context sensitive, dependent on the choices made in the order from left to right. There are three basic ways to specify a region to browse, by a range of chromosomal numerical positions, by a gene name or by an accession number. More flexibly, instead of exact positions, one can also search for a descriptive term (such as “kinase inhibitor”) that is present in gene records. Some restrictions are worth noting. Chromosome positions must start with “chr“. Gene names recognized by the browser appear to be limited to those in RefSeq and Ensembl entries. Remarkably, most if not all named miRNA genes, like lin-4, let-7, lsy-6 and 170 mir- loci are excluded from the Genome Browser. It is perhaps a temporary hiccup that may get resolved.
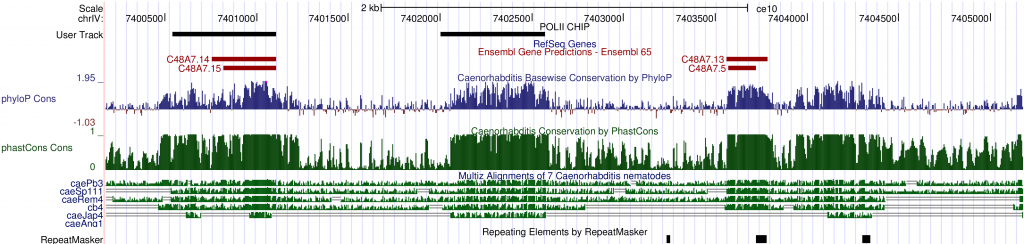
Once a region is selected, the Genome Browser can display a wide selection of sequences and features as tracks. The tracks are easily customizable. One can add or remove specific tracks and change the order or looks of tracks to make them easier to browse. Several tracks based on multiple genomic sequences are grouped under the Comparative Genomics section. There is a multiple sequence alignment track (Multiz) and three conservation tracks (phyloP, phastCons and conserved elements) to graphically display the results of conservation analyses. Scanning the genome with these tracks turned on, one can quite easily spot areas that show significant cross-species conservation, possibly implicating functional domains. For example, on chromosome IV, between C48A7.14 and C48A7.13, there is a 530-bp region (chrIV:7402060-7402590) that is highly conserved between C. elegansand five other species and yet there is no existing annotation. It could be an extension of a gene model nearby or a new gene.
One important extension of the Genome Browser is the ability to add custom tracks. Custom tracks allow users to incorporate their own or third party data into the browser so that imported sequence annotations can be inspected in the context of existing ones. For example, a large collection of diverse, sequence-based experimental data have been published by the ModEncode project. There are experiments assessing every part of the genome for its involvement in expression regulation under diverse biological conditions. ModEncode data sets may be downloaded as sequence features in a compatible format and included as custom tracks in the Genome Browser. As an example, I added a track for modencode_174 (labeled as “User Track: POLII CHIP”), which marks genomic regions that have been identified as potential binding sites for RNA polymerase II. There is substantial overlap between a potential Pol II binding site and inter-species conserved bases intervening C48A7.14 and C48A7.13. This observation further supports the possibility that this 530-bp stretch of sequence is functionally important, and may be expressed.
Figures
Articles submitted to the Worm Breeder's Gazette should not be cited in bibliographies. Material contained here should be treated as personal communication and cited as such only with the consent of the author.
Leave a Reply
You must be logged in to post a comment.